Inside the app
Everything your inference session is doing, at a glance.
The Usage tab surfaces token consumption, request timing, cost equivalence, and per-model breakdowns — all stored locally. No cloud dashboard, no data shared.
Works out of the box. For everyone.
No terminal setup, no YAML files, no Docker. Download, open, pick a model. Aether handles the rest — runtime packages, key management, updates. If you can install an app, you can run local AI.
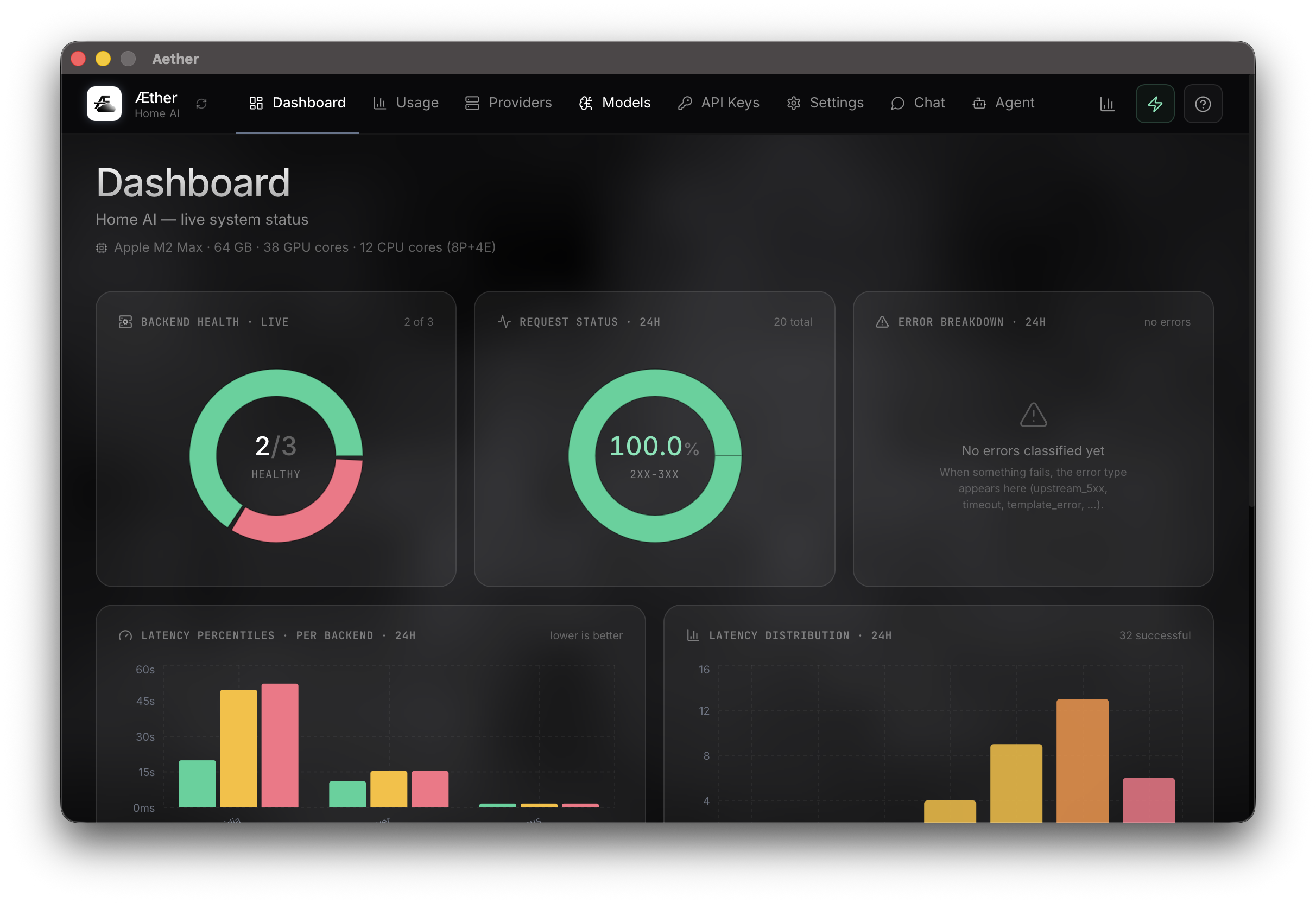
Tokens, requests, latency, top client.
Eight live metrics: total tokens, cloud-cost equivalent, request count, avg latency, top model, error count, provider health, and which client sent the most requests — opencode, Claude Code, curl, or anything else.
Millions of tokens. $0.
Every token routed to a local model costs nothing. The Est. Cost counter stays at zero. The cloud equivalent column shows what the same volume would cost on a hosted API — the difference is what stays in your pocket.